"支持视觉Transformer 增量学习的元注意力机制"论文被国际顶会CVPR录用
Tue Feb 01 14:39:47 CST 2022
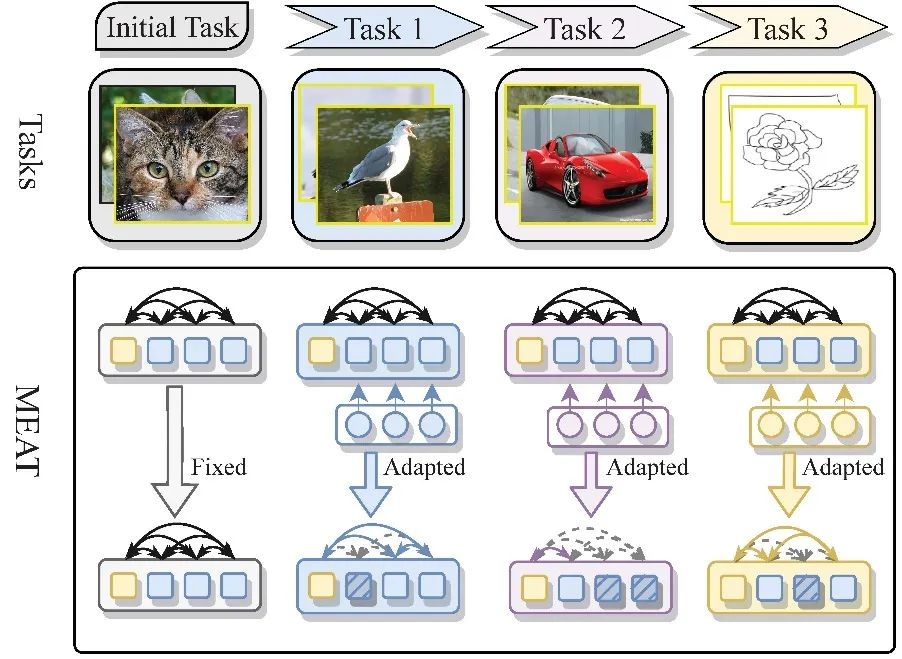
AZFT-计算机视觉与视频分析实验室宋明黎教授团队论文 “Meta-attention for ViT-backed Continual Learning” 被国际顶级计算机视觉会议CVPR录用。论文作者为薛梦琦,张皓飞,宋杰,宋明黎。增量学习在计算机视觉领域是一个研究已久的领域,意在研究如何让一个深度模型在不忘记已经掌握的知识的情况下持续性地学习新的任务。如何避免深度模型的灾难性遗忘 (catastrophic forgetting)一直是增量学研究的重点。视觉Transformer(ViT)最近开始挑战CNN在计算机视觉领域的统治地位,而传统的针对CNN的增量学习的方法已不适用ViT,因此我们在这篇论文中提出一种基于mask的增量学习的方法(MEAT),将一个已经预训练的好ViT适用于各种新任务,同时完全不损失在已经学习的任务上的精度。MEAT主要指对于ViT的两个组成模块,MHSA与FFN,而提出。与之前的基于mask的增量学习的方法不同,MEAT中的mask分为两部分:对于MHSA的mask和对于FFN层参数的mask。对于MHSA中的自注意力模块,我们使用mask来实现对注意力的元注意力——隔离一部分的image token,对不同的新任务来定制不同的新的自注意力模式。MEAT实现了各个新任务独有的注意力模式,同时任务相关的mask避免了任务间的互相影响与灾难性遗忘的问题。同时,针对FFN参数的mask为不同的任务保留不同的已经预训练好的参数,也是对参数的元注意力。我们的方法探索了针对ViT的增量学习的问题,大量的实验表明我们的方法在公共数据集上表现了优越的性能,超越了同样CNN架构的方法4.0% 到6.0% 的准确率。