随着人工智能技术的不断发展,知识图谱作为人工智能领域的知识支柱,以其强大的知识表示和推理能力受到学术界和产业界的广泛关注。近年来,知识图谱在语义搜索、问答、知识管理等领域得到了广泛的应用。多模态知识图谱与传统知识图谱的主要区别是,传统知识图谱主要集中研究文本和数据库的实体和关系,而多模态知识图谱则在传统知识图谱的基础上,构建了多种模态(例如视觉模态)下的实体,以及多种模态实体间的多模态语义关系。当前典型的多模态知识图谱有DBpedia、Wikidata、IMGpedia和MMKG。
多模态知识图谱的应用场景十分广泛,它极大地帮助了现有自然语言处理和计算机视觉等领域的发展。多模态结构数据虽然在底层表征上是异构的,但是相同实体的不同模态数据在高层语义上是统一的,所以多种模态数据的融合对于在语义层级构建多种模态下统一的语言表示模型提出数据支持。其次多模态知识图谱技术可以服务于各种下游领域,例如多模态实体链接技术可以融合多种模态下的相同实体,可应用于新闻阅读,同款商品识别等场景中,多模态知识图谱补全技术可以通过远程监督补全多模态知识图谱,完善现有的多模态知识图谱,多模态对话系统可用于电商推荐,商品问答领域。
2 多模态预训练
预训练技术在计算机视觉(CV)领域如VGG、Google Inception和ResNet,以及自然语言处理(NLP)如BERT、XLNet和GPT-3的成功应用,启发了越来越多的研究者将目光投向多模态预训练。本质上,多模态预训练期望学习到两种或多种模态间的关联关系。学术界的多模态预训练方案多基于Transformer模块,在应用上集中于图文任务,方案大多大同小异,主要差异在于采用模型结构与训练任务的差异组合,多模态预训练的下游任务可以是常规的分类识别、视觉问答、视觉理解推断任务等等。VideoBERT是多模态预训练的第一个作品,它基于BERT训练大量未标记的视频文本对。目前,针对图像和文本的多模态预训练模型主要可以分为单流模型和双流模型两种架构。VideoBERT,B2T2, VisualBERT, Unicoder-VL , VL-BERT和UNITER使用了单流架构,即利用单个Transformer的self-attention机制同时建模图像和文本信息。另一方面,LXMERT、ViLBERT和FashionBERT引入了双流架构,首先独立提取图像和文本的特征,然后使用更复杂的cross-attention机制来完成它们的交互。为了进一步提高性能,VLP应用了一个共享的多层Transformer进行编码和解码,用于图像字幕和VQA。基于单流架构,InterBERT将两个独立的Transformer流添加到单流模型的输出中,以捕获模态独立性。
3 知识增强的预训练
近年来,越来越多的研究人员开始关注知识图(KG)和预训练语言模型(PLM)的结合,以使PLM达到更好的性能。K-BERT将三元组注入到句子中,以生成统一的知识丰富的语言表示。ERNIE将知识模块中的实体表示集成到语义模块中,将令牌和实体的异构信息表示到一个统一的特征空间中。KEPLER将实体的文本描述编码为文本嵌入,并将描述嵌入视为实体嵌入。KnowBERT使用一个集成的实体链接器,通过一种单词到实体的注意形式生成知识增强的实体广度表示。KAdapter为RoBERTa注入了事实知识和语言知识,并为每种注入的知识提供了神经适配器。DKPLM可以根据文本上下文动态地选择和嵌入知识,同时感知全局和局部KG信息。JAKET提出了一个联合预训练框架,其中包括为实体生成嵌入的知识模块,以便在图中生成上下文感知的嵌入。KALM、ProQA、LIBERT等研究还探索了知识图与PLM在不同应用任务中的融合实验。然而,目前的知识增强的预训练模型仅针对单一模态,尤其是文本模态,而将知识图融入多模态预训练的工作几乎没有。
多模态商品知识图谱的应用场景十分广泛,多模态结构数据虽然在底层表征上是异构的,但是相同实体的不同模态数据在高层语义上是统一的,所以多种模态数据的融合有利于充分表达商品信息。多模态商品知识图谱技术可以服务于各种下游领域,例如多模态实体链接技术可以融合多种模态下的相同实体,可以广泛应用于产品对齐,明星同款等场景中,多模态问答系统对于电商推荐,商品问答领域的进步有着重大的推进作用。但目前还相当缺乏有效的技术手段来有效融合这些多模态数据,以支持广泛的电商下游应用。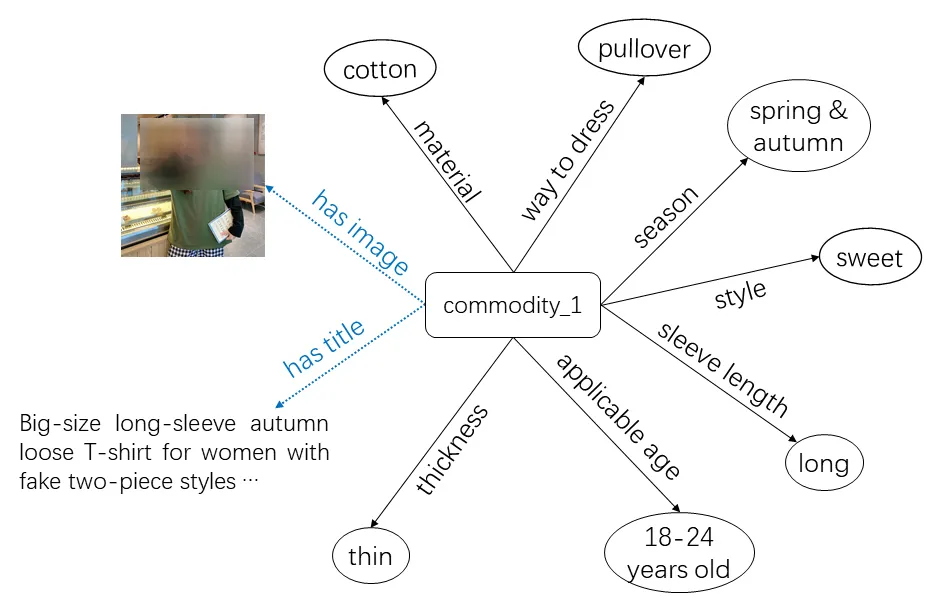 图1
图1
最近几年,一些多模态预训练技术被提出(如VLBERT、ViLBERT、LXMERT、InterBERT等),这些方法主要用于挖掘图像模态与文本模态信息之间的关联。然而,将这些多模态预训练方法直接应用到电子商务场景中会产生问题,一方面,这些模型不能建模多模态商品知识图谱的结构化信息,另一方面,在电商多模态知识图谱中,模态缺失和模态噪声是两个挑战(主要是文本和图片的缺失和噪声),这将严重降低多模态信息学习的性能。在真实的电子商务场景中,有的卖家没有将商品图片(或标题)上传到平台,有的卖家提供的商品图片(或标题)没有正确的主题或语义。图 2中的Item-2和Item-3分别显示了阿里场景中的模态噪声和模态缺失的例子。.png) 图2
图2
我们提出了一种在电子商务应用中新颖的知识感知的多模态预训练方法K3M。模型架构如图3所示,K3M通过3个步骤学习产品的多模态信息:(1)对每个模态的独立信息进行编码,对应modal-encoding layer,(2)对模态之间的相互作用进行建模,对应modal-interaction layer,(3)通过各个模态的监督信息优化模型,对应modal-task layer。
.png)
K3M在淘宝4千万商品上训练,其中每个商品包含一个标题,一张图片和一组相关的三元组。我们设置不同的模态缺失和噪音比率,在商品分类、产品对齐以及多模态问答3个下游任务上评估了K3M的效果,并与几个常用的多模态预训练模型对比:单流模型VLBERT,和两个双流模型ViLBERT和LXMERT。实验结果如下:.png)
.png)
.png)
1、饿了么新零售导购算法,离线算法AUC提升0.2%绝对值;在线AB-Test实验,流量5%,5天:CTR平均提高0.296%,CVR平均提高5.214%,CTR+CVR平均提高:5.51%;
2、淘宝主搜找相似服务,离线算法AUC提升1%,业务方反馈是很大的提升;目前在线AB测试中;
3、阿里妈妈年货节商品组合算法,在线算法,基于Emedding的实验桶(5.52%)CTR指标相较于另外2个实验桶(5.50%,5.48%)分别提高0.02%、0.04%的点击率,相对提高分别为0.363%、0.73%;
4、小蜜算法团队低意愿下的相似商品的推荐,整体增加这一路的召回情况下,转化能有2.3%到2.7%左右的提升,相对提升12.5%。之前版本相对提升11%。后续扩展到其他场景。

